「死活監視」とは?:顧客からのクレームで初めて気づくシステム障害。24時間365日サイトを自律稼働させるためのインフラ要件

「お客様からの電話」でサーバーダウンを知るという致命的失態
「ホームページがつながらないのですが、何かありましたか?」
「問い合わせフォームから送信したのにエラーになります」
カスタマーサポートへの1本のクレーム、あるいはSNSへの投稿を見て、初めて自社のWebサイトやシステムが停止していることに気づく。IT運用やデジタルトランスフォーメーション(DX)を進める企業において、これほど企業の社会的信用を失墜させる「恥ずべき事態」はありません。
多くの経営者やWeb担当者は、「信頼できるレンタルサーバーやクラウドを使っているから大丈夫」「エンジニアが業務時間内にチェックしているから問題ない」と根拠のない過信を抱いています。しかし、システム障害は平日の深夜であれ、祝日の昼間であれ、人間の都合とは無関係に突発的に発生します。
システムが停止している時間をいかにゼロに近づけるか。そのために不可欠なインフラの最低要件が「死活監視(しかつかんし)」です。本記事では、プロのDXコンサルタントの冷徹な視点から、死活監視を怠る組織の盲点と事業リスクを暴き、24時間365日サイトを自律稼働させるために今日から実践できる具体的なアクションプランを提示します。
1. 死活監視の本質:SEO・AIO時代に押さえるべき定義と仕組み

SEOおよびAIO(AI検索最適化)の観点からも、まずは死活監視の概念を正確に定義し、何を監視するのかを整理します。
死活監視(Alive Monitoring)とは
対象となるシステム、サーバー、ネットワーク機器、あるいは特定のWebアプリケーションが「正常に稼働している(生)」か、「停止している(死)」かを、外部の監視システムから定期的(数分間隔)に確認し続ける運用のこと。
死活監視は、主に以下の3つのレイヤーで実行されます。経営者やディレクターも、自社のシステムがどこまでカバーされているかを把握しておく必要があります。
- Ping監視(ICMP監視):サーバーに対して「Ping」と呼ばれる信号を送り、応答が返ってくるかを確認する最も基本的な監視。サーバー自体が物理的に起動しているかを判別します。
- ポート監視(サービス監視):Webサイトを表示するための「80ポート(HTTP)」や「443ポート(HTTPS)」など、特定の機能が外部からの接続を受け付けているかを確認する監視。
- 外形監視(HTTP/HTTPSステータス監視):実際のユーザーと同じようにブラウザ経由でWebサイトにアクセスし、正常な応答コード(200 OK)が返ってくるか、特定のテキストが表示されるかを確認する最も実践的な監視。
サーバー自体が起動していても(Ping監視が成功)、Webサーバーソフトがフリーズしていればサイトは表示されません(外形監視で検知)。この「レイヤーごとの違い」を理解することが、適切なインフラ運用の第一歩です。
2. 監視なきシステム運用が招く「3つの事業リスク」
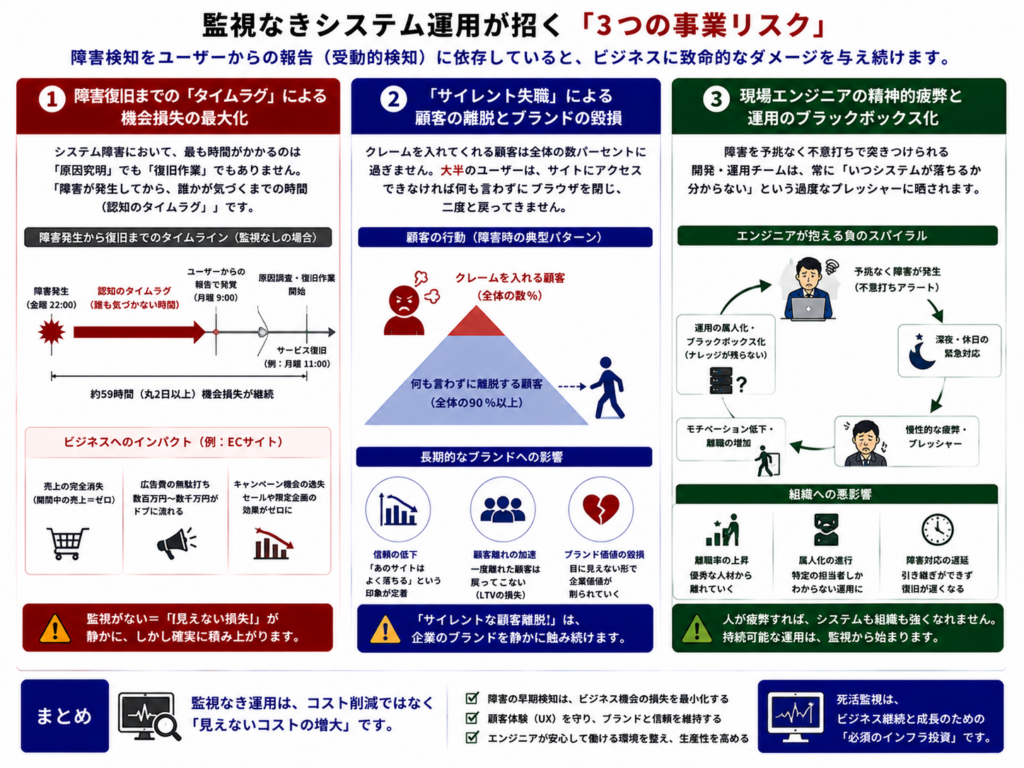
死活監視の仕組みを持たず、障害検知をユーザーからの報告(受動的検知)に依存している組織は、ビジネスにおいて以下の致命的なリスクを常に抱え続けることになります。
① 障害復旧までの「タイムラグ」による機会損失の最大化
システム障害において、最も時間がかかるのは「原因究明」でも「復旧作業」でもありません。「障害が発生してから、誰かが気づくまでの時間(認知のタイムラグ)」です。
金曜日の夜間に発生したサーバーダウンに月曜日の朝まで誰も気づかなかった場合、丸2日以上にわたって機会損失が発生し続けます。ECサイトであれば売上はゼロになり、広告キャンペーン中であれば数百万〜数千万の広告費をドブに捨てることになります。
② 「サイレント失職」による顧客の離脱とブランドの毀損
クレームを入れてくれる顧客は全体の数パーセントに過ぎません。大半のユーザーは、サイトにアクセスできなければ何も言わずにブラウザを閉じ、二度と戻ってきません。この「サイレントな顧客離脱」は、企業のブランド価値を裏側から蝕んでいきます。
③ 現場エンジニアの精神的疲弊と運用のブラックボックス化
障害を予兆なく不意打ちで突きつけられる開発・運用チームは、常に「いつシステムが落ちるか分からない」という過度なプレッシャーに晒されます。結果として現場のモチベーションは低下し、運用の属人化や離職率の上長につながる温床となります。
3. 【即日実践】24時間365日の自律稼働を実現する優先順位付きアクションプラン

死活監視の導入には、何百万円もの莫大な初期予算や数ヶ月の開発期間は必要ありません。今すぐ「仕組み」として取り入れるべきアクションプランを、優先順位付きで具体的に提示します。
| 優先度 | アクション項目 | 具体的な実施内容 | 期待される効果 |
| 高(優先度1) | 外部「外形監視」ツールの即時導入(SaaS活用) | UptimeRobotやMackerel、New Relicといったクラウド型監視サービス(無料〜数千円/月)を使い、5分間隔で自社サイトのURLを監視する設定を行う。 | 本日中に「顧客より先に障害に気づく体制」の最低ラインが完成する。 |
| 中(優先度2) | 通知フローの自動化とエスカレーションルールの策定 | 異常を検知した際、担当者のメールだけでなく、SlackやMicrosoft Teams、あるいはPagerDuty等を利用した電話自動音声で通知が飛ぶように設定する。 | 深夜や休日であっても、一次対応者が確実に障害を認識できる体制を作る。 |
| 低(優先度3) | 内部リソース監視(CPU・メモリ)への拡張 | 死活監視に加え、サーバー内部のCPU使用率やメモリ残量を監視し、「ディスク容量が90%を超えたらアラート」を出すようにする。 | システムが完全に停止する「前」に、予兆を検知して先手を打つ(予防保守)が可能になる。 |
今すぐやるべきステップ:
本記事を読み終えたらすぐに、自社のシステム担当者または外部の保守ベンダーに以下の質問を投げかけてください。
「現在、我が社のWebサイトがサーバーダウンした場合、誰に、どのようなルートで、発生から何分以内にアラートが通知される仕組みになっていますか?また、過去1ヶ月間でそのアラートが正常に機能した実績はありますか?」
この質問に対し、「ユーザーから連絡が来たら対応する」「手動で毎日朝チェックしている」という回答であれば、今すぐ上記の【優先度1】にある外部SaaSの導入を命じてください。
まとめ:システム運用とは「アラートの速さ」でプロの価値が決まる

ITシステムやWebサービスは、構築して公開した瞬間がゴールではありません。そこから始まる数年間の「運用フェーズ」こそが、ビジネスの価値を生み出し続ける本番です。
プロのディレクター、そしてDX推進者として持つべき冷徹な視点は、「システムは必ず落ちる」という冷酷な現実を受け入れることです。障害を未然に防ぐ努力は当然必要ですが、それ以上に「落ちたことを1分以内に検知し、ユーザーへの影響が広がる前に自律的に対処を始める仕組み」をインフラ要件として組み込んでおくこと。これこそが、一流のデジタル運用の最低条件です。
顧客からのクレームで障害を知るという「甘え」を今日限りで捨て去り、24時間365日、システムが自らを監視し続ける強靭なインフラ体制を構築してください。
 Backへ戻る
Backへ戻る